“Did We Catch Everything?” How Ketryx Turns Risk Management into Proactive Product Intelligence
Table of Contents
I’ve been there: hundreds of pages into an 800-page risk management document, trying to trace whether Failure Mode #431 has adequate controls and whether those controls are actually verified.
I know this work matters. These documents protect patients. But at a certain point, the question stops being “is this right?” and starts being “did I catch everything?” Those aren’t the same question. That shift is where confidence in a risk assessment starts to erode.
Here’s what I’ve come to understand after years in this work: risk management at scale isn’t a cognition problem. It isn't busywork. It’s a process problem. Engineers aren’t missing things because they lack expertise. They’re missing things because the process asks humans to maintain thousands of relationships simultaneously, failure modes to controls, controls to requirements, requirements to tests, tests to evidence, across hundreds of failure modes, distributed across multiple tools, as the product continuously evolves and scales. No team maintains that manually without gaps.
The goal isn’t just getting through the document faster. It’s proactive product intelligence: transforming risk management from a reactive documentation exercise into a continuous, connected system that keeps pace with how devices are actually built.
“The question stops being ‘is this right?’ and starts being ‘did I catch everything?’ Those aren’t the same question.”
The problem with manual risk management at scale
As medical devices grow more complex, maintaining confidence that documentation is complete becomes exponentially harder, not from carelessness, but because the information is too complex for any one person to track manually
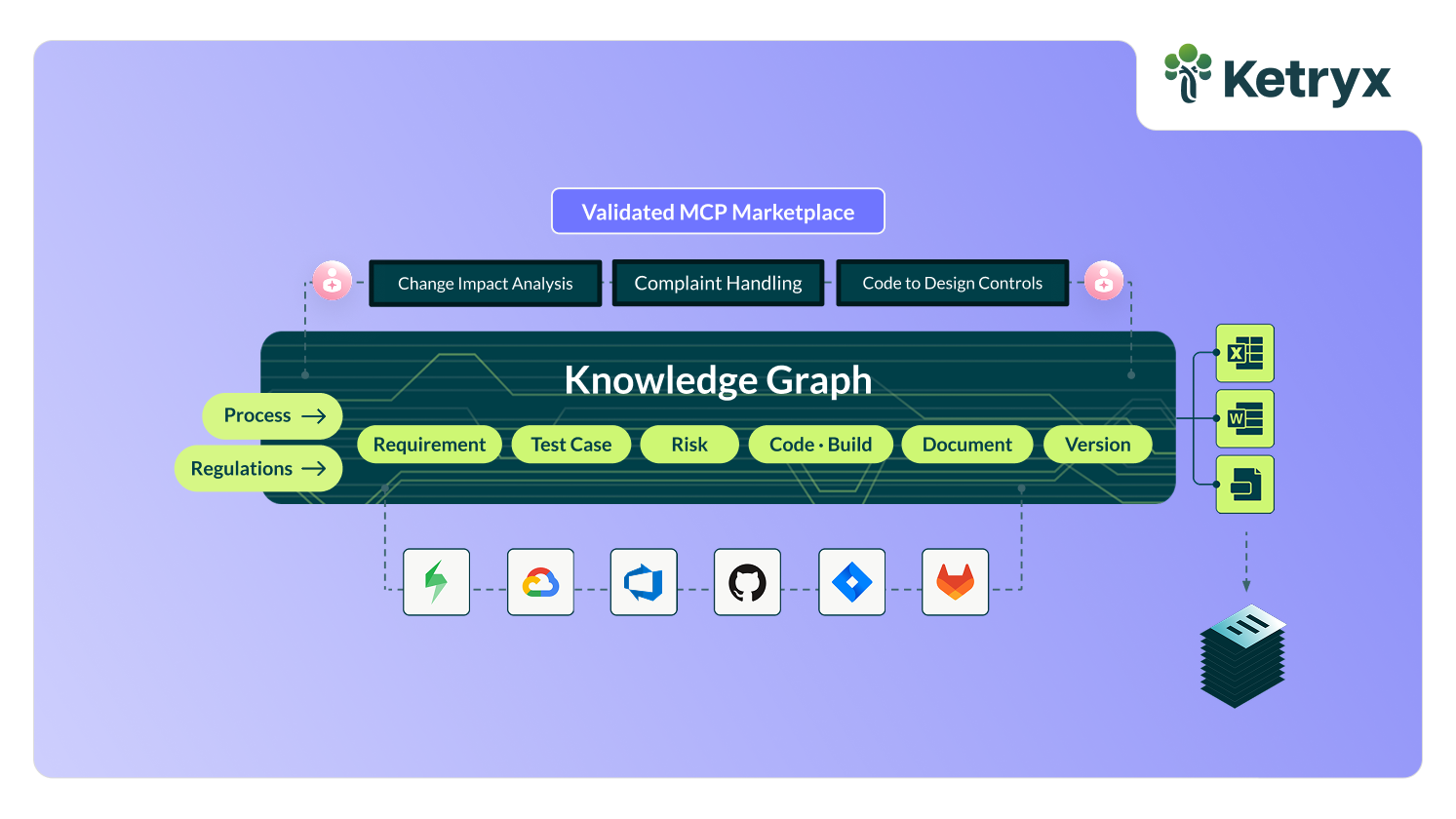
Managing a complex risk assessment across a modern toolchain means tracing failure modes through requirements in JAMA, design specs in Excel, test cases in TestRail, and verification evidence in Word. For a single failure mode, that trace is manageable. For hundreds, the mental overhead compounds quickly.
Each question in the graphic above is answerable in isolation. Answering all of them simultaneously, across hundreds of failure modes, is where the process breaks down.
The information exists somewhere in the toolchain. The problem is synthesizing it into a complete, coherent view: one that provides actual confidence rather than a reasonable assumption that nothing was missed. And that assumes the documentation hasn’t drifted since the last review.
When it does break down, the response is almost always reactive. A gap surfaces during an audit, a design review, or late-stage verification, and the team scrambles to reconstruct traceability after the fact. The fix is localized, not systemic. The same gap can reappear in a different failure mode, a different release, or a different product line.
The visibility failure runs deeper than comprehensiveness. Developers working in regulated environments don’t intend to create documentation gaps. They’re working in the tools they’ve always used: Jira, GitHub, and their IDE. Their risk assessment exists somewhere else, maintained by someone else, in a format most developers rarely open. That structural separation is what causes drift.
Consider what happens when a developer modifies code that's directly implementing a risk control. A reasonable performance improvement, nothing that changes the intended behavior. The PR passes review and merges. Three weeks later, QA flags it: that code was the verification evidence for Risk Control #89. The control is now unverified, and the gap surfaces right before release. Nobody made a mistake. The developer had no way of knowing that the code change touched risk management — that context lived in a different document in a different tool, invisible from where the work was happening.
The fix isn't better documentation habits or more process overhead. It's making risk control relationships visible in the environments where development actually happens, and keeping them current automatically, not reconstructing them manually.
“Risk management isn’t a cognition problem. It is a process problem.”
Where AI changes the equation
The shift AI-native platforms enable isn’t just speed. It’s confidence at speed. Those two things have always been in tension in risk management: moving faster meant accepting more risk that something was missed. Ketryx resolves that tension. Teams see up to an 90% reduction in documentation time, not by cutting corners, but by maintaining traceability automatically so engineers can focus on the judgment calls that actually require human expertise.
To be precise about what AI is and isn’t doing here: it isn’t making safety determinations. The human-in-the-loop remains central. Decisions about whether a control is adequate, whether a risk level is acceptable, and whether field evidence requires a mitigation update stay with the engineers and quality professionals who have the context and accountability to make them. What gets offloaded is the verification that the documentation supporting those decisions is complete. That work is exhausting, error-prone at scale, and not where engineering expertise adds the most value.
Post-market: the same problem, higher stakes
Everything above happens during development, when gaps are still correctable. Post-market is where the same underlying failure carries patient consequences: incomplete traceability, documentation that’s drifted from reality, a risk assessment that doesn’t reflect what the device actually does.
Post-market surveillance reveals how a device actually performs. Failure modes that weren’t anticipated during development, probability estimates that don’t hold up against field data, and evidence that should reshape both the current product and the next design revision. The comprehensiveness problem doesn’t end at launch. It compounds.
From hoping to knowing
I’ve spent time on page 673 of a risk management document. I know what it feels like to be done but not certain. To close the file and still wonder whether you caught everything. That question doesn’t stay in the document. It follows the device into production, into the field, and into every audit.
“All auditors were amazed by the level of detail, linkage, and control… Ketryx is an efficient and compliant solution for medical device software development.” — Mihir Naik, Sr. Director of Quality, Vektor Medical (3 successful audits, including a leading notified body in 2024)
That’s not a documentation story. That’s a confidence story.
The difference AI makes isn’t getting to page 673 faster. It’s getting there and knowing, not hoping, that the answer to “did we catch everything?” is yes.

Megan is a Technical Product Marketing Manager at Ketryx with 6 years of experience in medical device development at Abbott and iRhythm Technologies. She previously led cross-functional teams at Abbott and iRhythm, working across the total product lifecycle (TPLC) with engineering, clinical, quality, regulatory, and commercial stakeholders. She has supported FDA Class I-III device development from early product definition through design transfer, including multiple successful 510(k)s, PMA-S, and EU MDR submissions.
Megan is passionate about using product storytelling to make complex regulatory technology more understandable, meaningful, and impactful.